DrM:通过最小化休眠率提升视觉RL
0 Abstract
背景:视觉强化学习 (Vision RL) 在连续控制任务中展现出巨大潜力。
困难:目前的算法在性能的各个方面,如样本效率、渐近性能以及它们对随机种子选择的鲁棒性方面,仍然不尽如人意。
困难核心原因:现有 Vision RL 方法的一个主要缺点是,智能体在早期训练中经常表现出持续的不活跃性,从而限制了它们有效探索的能力。我们揭示了:智能体倾向于运动不活跃探索与其策略网络中缺乏神经元活动之间存在显著关联。
为了量化这种不活跃性,我们采用休眠率 (dormant ratio)作为衡量 RL 智能体网络不活跃性的指标。我们还认识到,无论收到何种奖励信号,休眠率都可以作为智能体活动水平的独立指标。利用上述见解,我们引入了 DrM,这是一种通过积极最小化休眠率来指导智能体探索-利用权衡的方法。
2 Preliminary
Visual reinforcement learning的formulation就是普通的RL,除了输入有图像。由于输入中有图像,这让Vision RL多数是部分可观测问题,因而我们解决的问题多数是部分可观测马尔可夫决策过程 (POMDP) 。
Dormant Ratio of Neural Network 休眠神经元的概念最初由 Sokar et al. (2023) 提出,它旨在识别那些几乎不活跃、显示出最低激活水平的神经元。这个概念在分析神经网络行为时很重要,因为在线强化学习中使用的网络很容易失去其表达能力。
定义2.1. (Sokar et al., 2023) 考虑一个包含总共 个神经元的全连接层 。给定一个输入分布 ,令 表示神经元 在输入 下在层 的输出。第 层的第 个神经元的分数为():
如果 ,我们就定义层 中的神经元 为 -休眠神经元。
式解释:表示这一层的第i个神经元的“利用率”,并且有
定义2.2. 对于一个全连接层, 我们用 表示 -休眠神经元的数量。神经网络 的 -休眠率可以定义为:
式解释: 有很多层, 表示层数。表示第 层到底有多少神经元其实没用, 表示第 层神经元总个数。不难看出,上式分子是神经网络 中所有没用的神经元总个数,分母是神经网络 中所有神经元总个数,即 是没用神经元比例。显然, 越大, 越大。
伪代码:

3 Method
3.1 关键见解:休眠率与行为多样性
这篇文章的想法来源于实验中的一个发现:智能体休眠率的急剧下降 与 智能体在visual continuous control tasks中技能的获取 之间存在关联。
实验:作者用DrQ-v2(一种直接从像素观测中学习的无模型强化学习算法)在DeepMind Control Suite 的 Hopper Hop 任务训练过程中学习到的行为作为示例,如下图所示:智能体策略网络中休眠率的急剧下降是智能体执行有意义探索行为的内在指标。即,当休眠率高时,智能体通常固定不动,做不出有意义的动作;当比例降低了,说明智能体开始尝试有意义地探索,这时智能体逐渐学会爬行,到站立,最终跳跃。
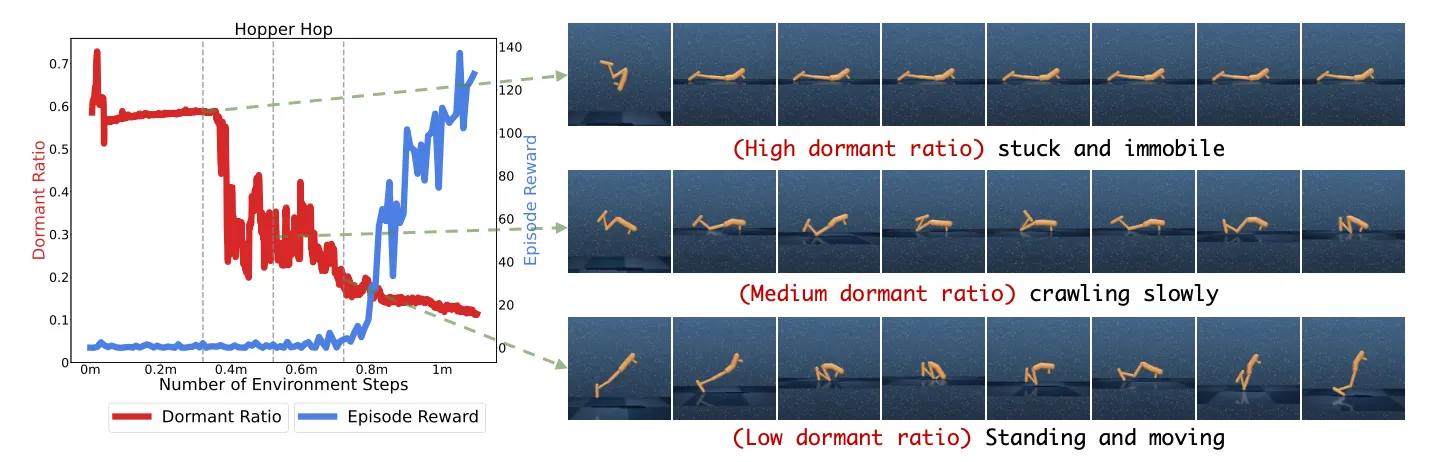 图2: (DrQ-v2 智能体在 Hopper Hop 任务中前 100 万帧训练期间的休眠率): 作者发现随着休眠率的下降,智能体逐渐获得了行动能力。尽管在此阶段奖励保持最低,但休眠率比奖励更能提供智能体初始学习进度的深刻衡量。
图2: (DrQ-v2 智能体在 Hopper Hop 任务中前 100 万帧训练期间的休眠率): 作者发现随着休眠率的下降,智能体逐渐获得了行动能力。尽管在此阶段奖励保持最低,但休眠率比奖励更能提供智能体初始学习进度的深刻衡量。
实验结论:休眠率的下降与智能体开始有意义的行动密切相关,标志着其脱离了先前单调或随机的行为。并且,这种转变可以在没有相应奖励增加的情况下发生——这表明休眠率是一种内在指标,它更多受到智能体行为多样性和相关性的影响,而非其获得的奖励,这突显了休眠率作为理解视觉强化学习智能体行为的有意义指标的价值。
受以上实验启发,作者尝试利用休眠率作为平衡exploration和exploitation的关键工具。具体来说,许多现有策略根据静态因素(如任务复杂度和训练阶段)调整探索噪声。然而,智能体的性能可能因任务和不同的初始化而波动,仅基于这些静态因素进行调整效率较低,并且通常需要大量针对特定任务的超参数微调。相比之下,根据智能体当前的性能定制探索噪声提供了一种更灵活有效的方法。虽然一种直观的方法是依赖奖励信号,但这种策略带来了以下挑战:
- 奖励值定义因不同任务和领域而异,需要领域特定知识进行解释和超参数调整。
- 在特定任务中,奖励无法完全指示智能体的潜在学习阶段。如上图所示,无论智能体是否掌握了运动或仍然停滞不前,它都可以获得差不多的奖励。
因此,休眠率作为调整探索与利用权衡的更有效指标出现,因为它忠实地反映了智能体行为的动态变化。鉴于此,作者设计出DrM算法,其核心是“较高的休眠率表明需要增加探索,而较低的休眠率则需要利用”。
3.2 DrM:通过最小化休眠率实现视觉强化学习
为了积极促进神经网络向降低其休眠率的方向演化,作者提出了三种机制:
-
休眠率引导的扰动 (Dormant-ratio-guided perturbation) 目标:当强化学习智能体网络显示高休眠率、失去表达能力时,主动扰动模型权重。 方法:扰动重置方法 (D’Oro et al., 2023; Ash & Adams, 2020),采用软重置,即将智能体所有参数在其先前值和随机初始化值之间进行插值:
这里 是扰动因子, 是重置前的网络权重, 是重置后的网络权重, 是随机初始化的权重。 的值由休眠率 控制:
其中 是扰动率。(简单想想,休眠率很小说明) 对比:这里的方法和NoisyNet (Fortunato et al., 2018b) 的方法有根本的不同,NoisyNet旨在通过在每个时间步向模型权重注入噪声来鼓励探索,但这里是受控随机。 伪代码:

-
唤醒探索调度器 (Awaken exploration scheduler) 目标:在休眠率高时强调以大的探索噪声进行探索,并在休眠率低时减少探索噪声。 作者没有使用原始 DrQ-v2 中线性衰减的探索噪声方差调度方法,而是引入了基于休眠率的唤醒探索调度器。具体来说,令 表示一个低休眠率阈值。当智能体的休眠率低于 时,我们将其定义为“已唤醒”。令 为智能体从训练开始到“被唤醒”所需的时间步数。探索噪声的标准差 定义为:
其中 是探索温度超参数. 伪代码:

-
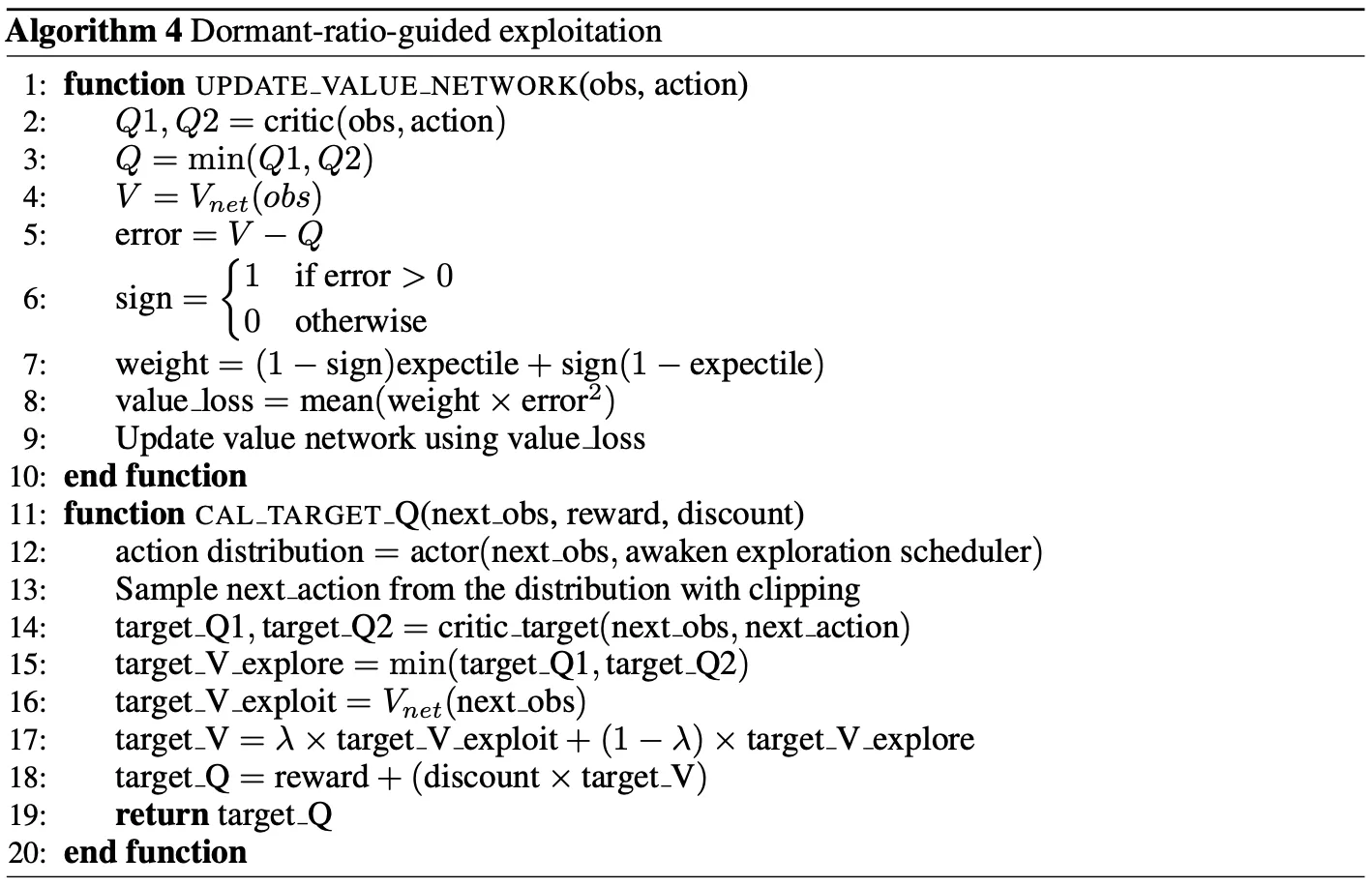
休眠率引导的利用 (Dormant-ratio-guided exploitation) 目标:引入一种在休眠率较低时巧妙地优先考虑利用的机制。 对于使用 Actor-Critic 算法的连续控制任务,critic的目标是近似, 但在训练早期, 是次优的且 经常被低估。因此,Ji et al. (2023) 建议使用分位数回归(expectile regression)近似 Q 值的高分位数(high expectile of Q), 使新 target value 为:
由于 比 值收敛更快,这种机制允许强化学习智能体快速利用其历史上成功的轨迹,而不会引入额外的过高估计。上式中 可以作为 exploitation 超参数, 越高意味着拟合的 函数侧重于从历史经验中( 包含了历史的更多信息)获取更多价值。 在此框架下,作者将 参数变成 的函数:
其中 是最大 exploitation 超参数, 是 exploitation 温度超参数, 和 分别代表休眠率及其阈值。 式解释:当智能体的休眠率超过阈值 时,选择较低的 以强调探索,反之亦然。
伪代码: